Exploring OpenAI's Whisper
The Revolutionary Text-to-Speech System

Status: 102
Introduction
"Ready to finally put your dulcet tones to good use? Look no further than the world of speech recognition!"
Speech recognition is a technology that allows computers to interpret and transcribe spoken language into written or electronic text. This technology has a wide range of applications, including virtual assistants, transcription services, and language translation. These systems can be trained to recognize and respond to specific voices, accents, and languages, making them useful for a variety of different tasks.
OpenAI's Whisper is a speech recognition system that uses machine learning to understand and transcribe spoken words. It was trained on a large dataset of multilingual and multitask data collected from the web, leading to improved accuracy and flexibility in recognizing different accents, backgrounds, and technical language. It can transcribe and translate multiple languages into English. The models and code for this technology are being open-sourced for use in building applications and for further research in the field.
Architecture
The OpenAI Whisper system uses a simple end-to-end approach based on the Transformer architecture. The input audio is then split into 30-second chunks, converted into a log-Mel spectrogram, and passed into an encoder. A decoder is trained to predict the corresponding text, including special tokens that allow the model to perform tasks such as language identification, timestamps, and multilingual transcription and translation. This allows the single model to handle a variety of tasks related to speech processing.
Approximately one-third of the data used to train Whisper is non-English, and the model is alternately tasked with transcribing the original language or translating it into English. This approach is particularly effective at learning speech-to-text translation and outperforms the current state-of-the-art on the CoVoST2 to English translation task without additional training.
I am no expert right now to dig deeper into it. So I gonna leave it to you. To learn more about the architecture, check out the Research paper.
Let's give it a try!
Install Whisper
pip install git+https://github.com/openai/whisper.git
Install FFmpeg
Whisper requires FFmpeg which includes a set of libraries and programs that can be used to encode, decode, and transcode multimedia files, as well as several command-line tools for performing common tasks.
# on Ubuntu or Debian
sudo apt update && sudo apt install ffmpeg
# on Arch Linux
sudo pacman -S ffmpeg
# on MacOS using Homebrew (https://brew.sh/)
brew install ffmpeg
# on Windows using Chocolatey (https://chocolatey.org/)
choco install ffmpeg
# on Windows using Scoop (https://scoop.sh/)
scoop install ffmpeg
Transcribe using Python
Import the whisper package
Load the model
Whisper provides five different model sizes, four with English-only versions. These models offer a range of options for balancing speed and accuracy. Check here for Available models and languages.Call the transcribe() function along with the audio file that you want to transcribe.
Print the result
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])
The transcribe()method processes audio from a file by dividing it into 30-second windows and using autoregressive sequence-to-sequence predictions on each window. It reads the entire file before beginning this process.
How the response will look like?
The below image shows the JSON response visualization of the transcribed audio. It has segments, tokens, text, language, etc.
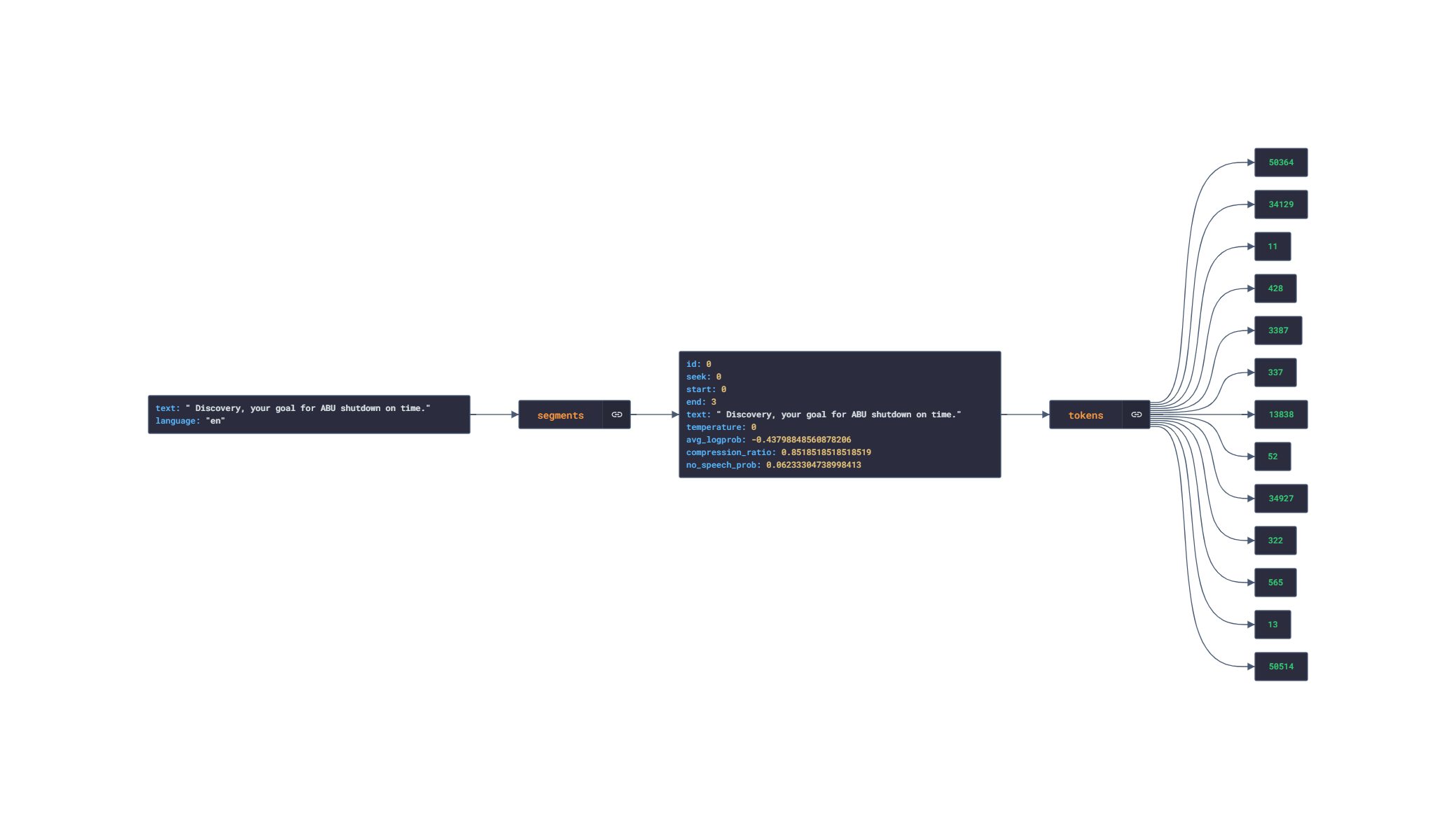
Example
I have an audio file extracted from a YouTube video that tells us the space facts. Let's try to transcribe it by running the code below.
import whisper
model = whisper.load_model("base")
result = model.transcribe("https://raw.githubusercontent.com/dotaadarsh/Aurable/main/space_facts.mp3")
print(result["text"])
Output
If you scaled the earth down to the signs of a cue ball, it would be smoother than the ball, Everest included. On Saturn, it may rain millions of pounds of diamonds every year. The atmosphere has such high heat and pressure that scientists think it can squeeze carbon into diamonds in mid-air. Jupiter is so big that it doesn't even orbit the sun. It revolves around a spot just above the sun's surface. The sun orbits that spot too, so it wobbles a little. Venus spins in the opposite direction than all the other planets in our solar system. Scientists think that the sun's gravitational pull flipped its axis 180 degrees. When the moon is at its furthest point in its elliptical orbit, all the planets in our solar system could fit in the space between our Earth and our Moon. The Earth is currently moving 1029 miles per hour, and our solar system is currently moving 490,000 miles per hour. It's a pretty good thing we have gravity to keep us on the planet. Our Milky Way galaxy is going to crash into the Andromeda galaxy in 4 billion years. The collision will likely fling our sun to another spot in the galaxy, but not destroy the Earth. The fastest thing in the universe is a pulsar called PSR. It's a collapsed star that spins 716 times per second. The molecular cloud Sagittarius B contains over 2 octillion gallons of alcohol. That's a lot of gallons. Scientists think that it would taste like raspberry rum.
Compare the result with the video. I know some of you may have skipped reading the transcript but just give it a try. Those are some really cool facts about space. All of that happens in just a couple of codes. It's amazing, right?
Conclusion
In conclusion, speech recognition technology has come a long way in recent years, allowing computers to accurately transcribe spoken words into written text. So what are you waiting for? Go and give it a try. Curious to know what people are building, check out the show and tell OpenAI's whisper GitHub Discussions page.
If you have any feedback, just let me in the comments or you can find me on Twitter at @dotaadarsh.
Thank you for giving my article a read. I appreciate your time and attention.




